Performance & Scalability
How to make your web app scalable so that it can accommodate thousands of users without having performance issues and making it fault-tolerant.
Many applications today are data-intensive, as opposed to compute-intensive. For example, many applications need to:
- Store data so that they, or another application, can find it again later (databases)
- Remember the result of an expensive operation, to speed up reads (caches)
- Allow users to search data by keyword or filter it in various ways (search indexes)
- Send a message to another process, to be handled asynchronously (stream processing)
- Periodically crunch a large amount of accumulated data (batch processing)
The questions that you should ask; 1) How much effort do you want to put in for improving performance? 2) What functionalities would be used most commonly? 3) What are the most resource intensive tasks?
Infrastructure
Web Server Overload
As we get more and more concurrent clients connecting to our web server, the web server would eventually run out of resources (like CPU and RAM) and exhaust. In this case, we need to increase the web server resources to accommodate more and more clients.
Basically, the architecture remains the same, it’s just that the server has been upgraded to accommodate more clients than before. This would solve the issue temporarily, but not permanently.
Single Point Of Failure
In order to achieve a fault-tolerant infrastructure, we set up multiple servers that host the same application, so that if any of the servers go down, we still have other servers running.
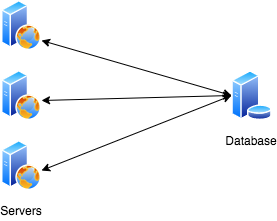
Distributing Traffic
To evenly distribute traffic across the servers, we use load balancers.
The load balancer acts as an intermediary between the clients and the servers, it knows the IP addresses of the servers and thus is able to route traffic from the clients to the servers.
 Having just one load balancer to do the work raises the issue we mentioned before; we have a single point of failure, if this load balancer dies out then we do not have a backup.
To overcome this issue, we can set up two or three load balancers where one would be actively routing the traffic and the others would be simply there as a backup.
Having just one load balancer to do the work raises the issue we mentioned before; we have a single point of failure, if this load balancer dies out then we do not have a backup.
To overcome this issue, we can set up two or three load balancers where one would be actively routing the traffic and the others would be simply there as a backup.
Factoring Out Sessions
To solve this issue, we can decouple the sessions to a different storage solution, for example to a Redis server. This way all the servers would be getting and storing their sessions from and to the Redis server. Of course, we can add redundancy for the Redis server as well to eliminate single point of failure.
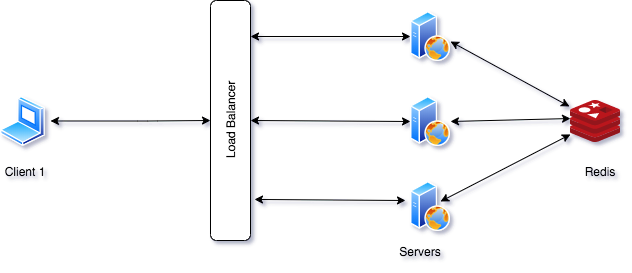
Infrastructure Automation
Most IT organizations face growing infrastructure size and complexity. With limited time and staff, IT teams often struggle to keep pace with this growth, resulting in delayed updates, patching, and resource delivery. Applying automation to common management tasks — like provisioning, configuring, deploying, and decommissioning — simplifies operations at scale, allowing you to regain control over and visibility into your infrastructure.
Database
Possibility Of Database Failure
we have only one database that is storing all the information, in order to introduce multiple database servers we use a technique known as replication.
Replication is all about making automatic copies of something.
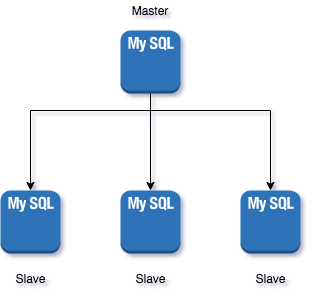 Every query that gets executed on the master database would be executed on the slaves.
Whenever the master database would pass out, one of the slaves would get promoted to become the master.
Every query that gets executed on the master database would be executed on the slaves.
Whenever the master database would pass out, one of the slaves would get promoted to become the master.
Another paradigm is master-master architecture in which we have multiple masters connected to multiple slaves.
Database Queries Are Still Expensive
Having more than ten million users query from the same database is not that good as it would take the database some time to search for a single user in the midst of ten million users.
Sharding is used to increase database efficiency so that queries take less time to get executed.
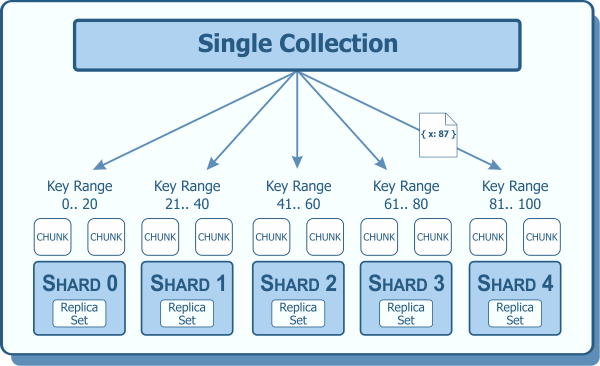
Sharding is basically to have two or more databases so that queries could be split between them according to some metric. For example, we could have two databases and we could reserve the first database for users whose name begins with A-M and the second database for users whose name begins with N-Z.
Software
Queries Are Expensive
For a small application, that is handling around a hundred to a thousand users, querying a database is non-trivial when it comes to performance, but when the question of serving more than a million users arises it is somehow tricky.
Implementing a cache (such as Redis) can reduce the load on your database drastically, if your application is making the same queries over and over.
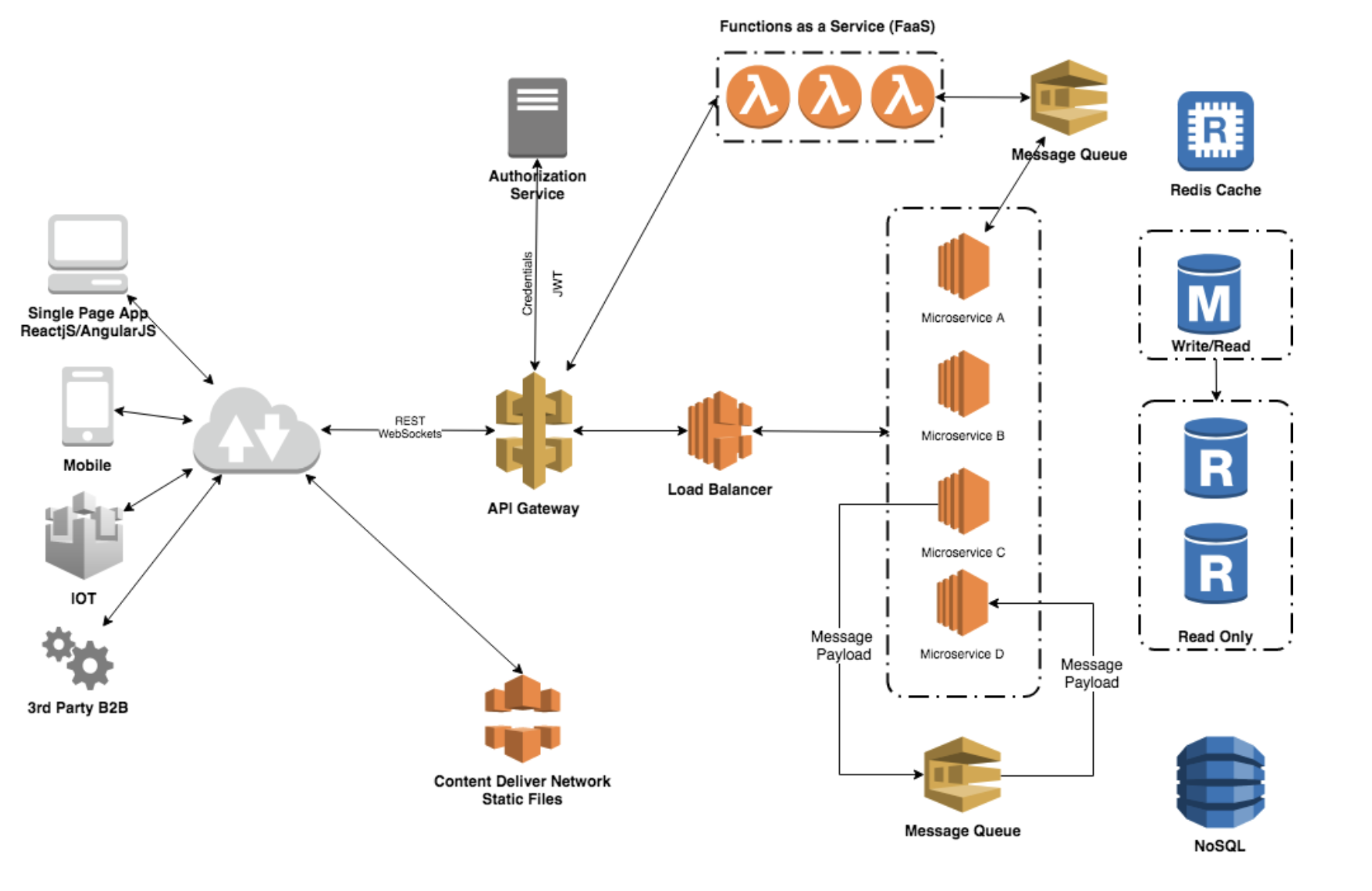
Scale with Microservices Architecture
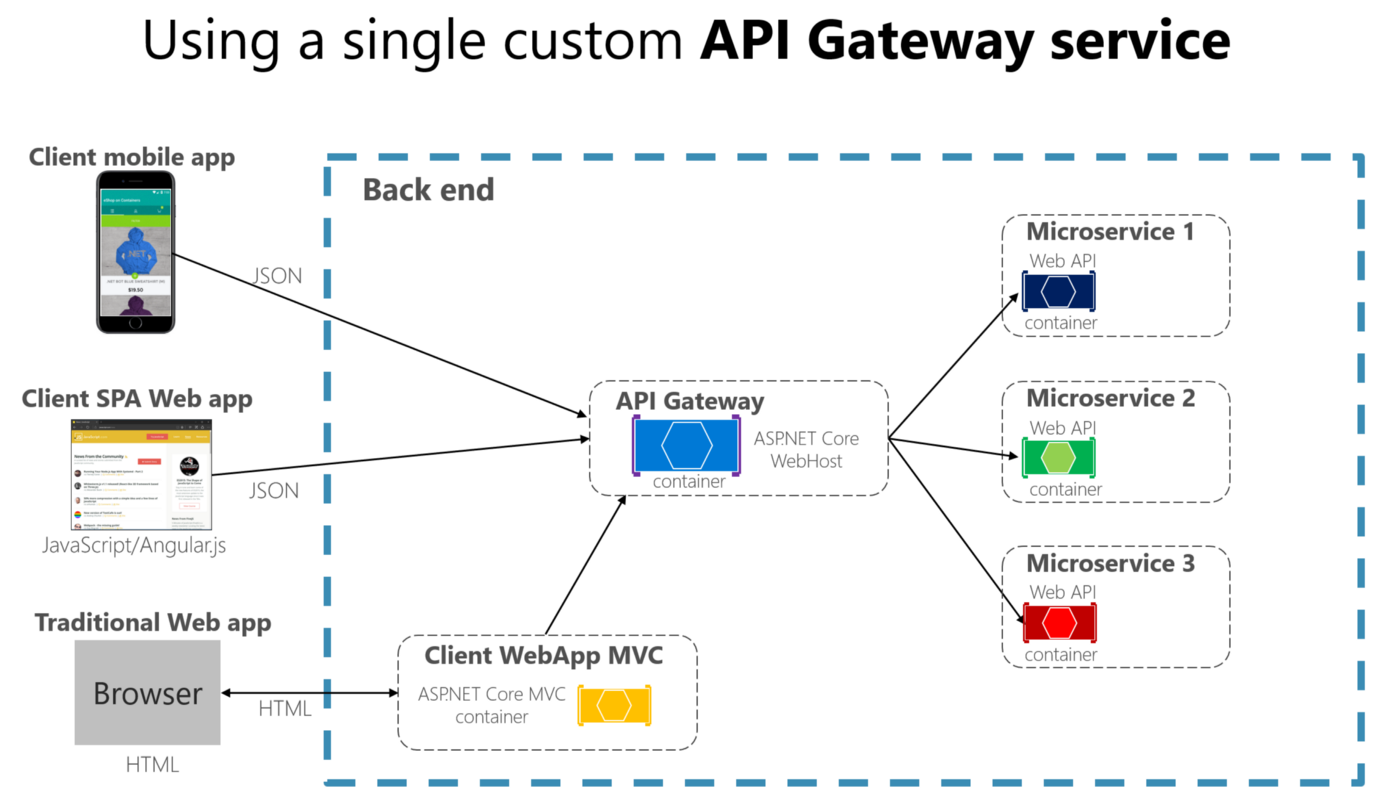
Asynchronous and Background Workers
Every application has some heavy lifting jobs. Performing this operation in realtime would put a lot of unnecessary load on your application. A better way of doing this would be to have a script running in the background that periodically checks for new requests, does all the heavy lifting and notifies your application once the operation is complete.
Message queues are commonly used in such situations, but even a simple script running in the background would be better than doing such operations in realtime.
Decoupled Architecture
Building your application in a decoupled manner will allow you to allocate proper resources to the components that need them, when they need them.
Stateless Services
Building stateless services is important because once you are ready to scale your application you need services that can be started or stopped without any impact on the overall system.
Build fault tolerant systems
Overall
In this article, we walk through some of the architectural designs that web applications can be scaled by explaining the core concepts.
Thanks to Harith Javed Bakhrani for his contribution